

Continuellement à la recherche de nouveaux outils pour nous permettre de gérer toujours mieux nos infrastructures virtuelles (en particulier depuis certains incidents récents), je me suis penché récemment sur la problématique de la supervision « temps réel » de nos clusters VMWare. En effet, nous utilisons depuis longtemps vRealize Operations (et VCOps avant lui), qui nous rend au quotidien de fiers services, nous permettant surtout de gérer sur la durée nos capacités de production. Cependant, celui-ci n’est vraiment utile que pour du capacity planning et de l’analyse de comportement/performance sur le moyen et long terme, pas du tout pour de la supervision temps réel. L’objectif pour nous est de disposer d’un logiciel permettant de détecter presque d’une seconde à l’autre une dégradation ou un incident spécifique, pour réagir de manière plus efficace… et si possible avant même que nos utilisateurs ne soient impactés.
Alors, effectivement, il existe chez VMWare vRealize LogInsight qui fait partie des options que j’ai étudié, mais malgré la « promotion » disponible depuis le début de l’année, à savoir le fait que tout possesseur d’une licences vCenter était éligible à un pack de 25 « entités » (avec quelques limitations opérationnelles qui plus est), pour pouvoir couvrir l’ensemble de notre environnement, nous devions acheter des licences complémentaires.
Et c’est ce week-end que j’ai découvert SexiLog. Sur le papier cette solution présente quasi tous les avantages qu’on peut attendre d’une supervision « live », pilotée par les événements déclenchés dans les logs mêmes de nos ESXi. De plus, elle est basée sur ElasticSearch et Logstash, des outils Open Source reconnus dans le monde de la corrélation de logs et parfaitement adaptés à leur tâche. Enfin, cerise sur le gâteau, SexiLog est Open Source elle aussi et développée par des petits Français !
Alors ? Ai-je trouvé le Saint-Grâal de l’analyse temps réel ? Réponse dans la suite 🙂
SexiLog est un intégré qui regroupe différents composants chargés chacun de réaliser une tâche spécifique. J’en ai déjà évoqué deux dans mon introduction, ElasticSearch pour la partie moteur de recherche et LogStash pour le stockage des données. Si vous souhaitez en savoir plus sur l’architecture globale, rendez-vous directement sur le site officiel où tout cela est très bien expliqué. Le système est capable d’ingérer des données de deux manières nativement : par réception d’évennements de type syslog (UDP 514) ainsi que via des traps SNMP (UDP 162).
Vous comprenez tout de suite qu’il va falloir reconfigurer vos ESXi pour pouvoir exploiter la solution (contrairement à SexiGraf, par exemple… mais cela fera l’objet d’un autre article !). Le plus simple de mon point de vue est de modifier/adapter un Host Profile afin d’y ajouter l’IP de la cible syslog, la VM SexiLog en l’occurence, mais vous pouvez aussi le faire le live en utilisant une commande shell « esxcli ». Voici la liste « brut » des commandes à passer sur chacun de vos serveurs :
|
1 2 |
esxcli system syslog config set --loghost="udp://ip_de_votre_vm_sexilog:514" esxcli network firewall ruleset set --ruleset-id=syslog --enabled=true |
Distribué sous forme d’OVA, SexiLog est très simple à installer, tellement simple que je ne vous ferai même pas l’affront de vous montrer comment tout cela se configure. La préparation de la VM prend 5 minutes maximum et vous êtes déjà prêt à lui faire absorber vos logs.
Ensuite, pour la supervision, il vous suffit de vous connecter à l’interface « tableau de bord » (le composant Kibana), ainsi, logguez-vous au portail web en pointant votre navigateur sur l’URL
http://IP_de_la_vm_sexilog. Vous arrivez sur un dashboard par défaut recensant le nombre d’événements reçus sous forme d’histogramme ainsi que la liste des 50/100 derniers. SexiLog est clairement dédié à la supervision VMWare, même si techniquement, vous pouvez lui envoyer bien d’autres type de logs. A ce titre, vous disposez d’une liste déjà bien fournie de tableaux de bord présentant des extractions de logs spécifiquement conçus pour vous apporter une visibilité particulière sur certains type d’événements ou certains niveaux de criticité. Voici quelques copies d’écrans de tableaux de bord intégrés (après quelques heures de récolte sur notre production) :






Il existe aussi des dashboards plus spécifiques qui nécessitent de modifier un peu le comportement de vos ESXi en matière de « verbosité » sur les logs qu’ils envoient à SexiLog. En particulier, il est possible (voir le billet suivant sur Hypervisor.fr) de récupérer des statistiques de performances de votre stockage VMWare en quasi temps réel (toutes les 4 secondes). Après modification de configuration de vos ESXi, vous pourrez recevoir ce type de messages et les exploiter pour en faire des graphiques. L’éditeur de tableau de bord est particulièrement bien pensé et après une petite phase d’adaptation et de compréhension de la logique, j’ai pu développer un tableau de bord dédié qui présente les IOps et les latences de chaque datastore pour nos environnements TIER1 et TIER2, et tout cela en temps réel ! Quelle confort avancée par rapport à tous nos outils existants !


Enfin, on peut facilement modifier les dashbords existants pour les adapter à nos besoins. Ici, un exemple de modification du tableau de bord de suivi des commandes de snapshots (avant/après):
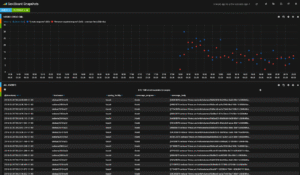

Clairement, les possibilités sont assez énormes et SexiLog s’approche de la perfection pour de la supervision « live » de votre production. De plus, en dehors du strict point de vue du monitoring en temps réel, il est aussi possible d’utiliser SexiLog pour réaliser des diagnostics très précis et pointus notamment autour du comportement des serveurs ESXi et de leurs alertes. Enfin, grâce à la masse d’événements reçus, on peut envisager aussi de réaliser de la corrélation de logs pour extraire une faiblesse ou des problèmes de paramétrage qui dépassent le cadre de chaque machine physique. Par exemple, avec des tableaux de bord comme celui du « VMotion DownTime ». VMotion est, comme vous le savez sans doute, une des fonctions avec Fault Tolerance qui réclame la synchronisation et la communication la plus parfaite entre le serveur source et le serveur cible. Le « downtime » donne une visibilité précise exprimée en milli-secondes du temps d’indisponibilité réel de chaque VM déplacée, entre le moment ou la session de migration démarre et le moment ou la VM tourne désormais complètement sur la cible. Un downtime VMotion élevé peut révéler des problèmes spécifiques sur votre réseau ou des difficultés pour vos ESXi d’absorber cette charge complémentaire, même temporairement.
Bref, vous l’aurez compris, j’ai été complètement emballé par SexiLog : Open Source, puissant, facile d’installation et d’utilisation, ergonomique, BEAU (si si, ça compte) et gratuit ! Tout est là pour qu’il fasse partie de vos environnements, en embuscade s’il vous manque des metrics ou en cas d’urgence, c’est une de ces perles d’Open Source que l’on rencontre sur la toile, réalisée par des passionnés experts de leur domaine. Jetez-vous sur SexiLog, essayer c’est l’adopter, assurément !
0 réponse
hello Cédric, effectivement l’outil semble séduisant !
Merci !
Tu complète pas avec graphana et smi-s pour ton infra de stockage ?
smis-s on a, effectivement, pour le provisionning VPlex/VNX auto. Par contre, Graphana connait pas, donc zoo, vé googler 🙂
Thx Xav !
Ha mais si je connais 🙂
Ya d’ailleurs chez les mêmes, SexiGraf, qui s’appuie précisément sur Graphana pour faire du graph « long terme » sur les infras ESXi/VMWare. J’ai testé mais pour le moment, j’ai pas mal de bugs ou d’erreurs sur les graphs, du coup, pas encore pris le temps de creuser. Et puis, au boulot on a vRealize Operations qui fait le taff coté capa planning 😉
Dit moi t’a des alternatives à vrops pour la supervision des vm ?
Tu peux essayer SexiGraph http://www.sexigraf.fr/ capacity planning et reporting. C’est vraiment top mais pas encore eu le temps de le tester jusqu’au bout (j’ai eu un souci de stabilité lors de mon dernier test).