
Entretien avec Charles et Killian, créateurs de Portabase

Journée riche aujourd’hui chez vBlog ! En réalité, je planche depuis quelques jours sur plusieurs articles en parallèle… ce qui explique peut-être cette frénésie, car ils arrivent un peu tous en même temps. Après ma récente présentation de Portabase, ayant trouvé son approche particulièrement séduisante. Elle reflète les valeurs que je défends depuis plus d’un an (souveraineté, open source …). Bref, tout ça pour découvrir que Portabase cache en réalité une jeune société et deux ingénieurs talentueux et convaincus… Découvrons-les ensemble dans cet entretien !
Dit Jamy, C’est quoi un bastion ?

Depuis quelques mois, je me documente sur la notion de bastion. Plus j’avance dans mes lectures, plus je suis convaincu qu’il s’agit d’un fondamental pour une prod digne de ce nom. Pourtant, ce sujet est souvent relégué au second plan, comme s’il n’était pas prioritaire et qu’on « avait pas sous ». Or, c’est précisément cette négligence qui me semble être une erreur majeure : cette approche devrait au contraire figurer parmi les briques de base de tout environnement protégé aujourd’hui.
Le layering des conteneurs, Containerd et Docker

Le matin d’une journée de boulot… la première chose que je fais (après ma douche), c’est de regarder si mon blog va bien. Évidemment, j’ai UptimeKuma pour m’aider à voir d’un coup d’œil comment se passe ma mini-prod… mais aujourd’hui, quelle n’a pas été mon horreur de constater que le / de mon serveur dédié, où se trouve notamment vBlog.io, était full…
La pépite du Lundi matin : Sencho

J’ai passé ma journée d’hier (oui, un dimanche… désolé pour ceux qui préfèrent aller à la plage) à installer et découvrir Sencho, la nouvelle pépite de ce lundi. C’est une solution open-source de gestion multi-serveur d’environnements Docker (une de plus j’ai envie de dire …), conçue pour simplifier le déploiement et l’orchestration de conteneurs, sans passer […]
Vous connaissez Julien ?

Je lance un nouveau moyen d’essayer de vous faire connaître un peu tous les compagnons d’armes que j’ai pu croiser durant toutes ces années de boulot dans l’IT. Vous le savez sans doute : mon kiff, c’est notamment de transmettre tout ce que j’ai pu apprendre par moi-même ou via mon expérience de prod, mais aussi de partager cette connaissance avec le plus large public possible. Aujourd’hui, c’est Julien qui passe à la moulinette !
Petite expérience : à quoi je sers en fait ?

Je vous propose une petite expérience avec Jarvis, mon agent IA que j’utilise de plus en plus, surtout pour aller plus vite et vous proposer des articles toujours irréprochables sur les plans orthographique et grammatical. Jusqu’à présent, c’était toujours moi qui écrivais le premier jet, et je ne lui demandais que de peaufiner ou d’améliorer le tout.
Présentation d’une nouvelle pépite : Portabase
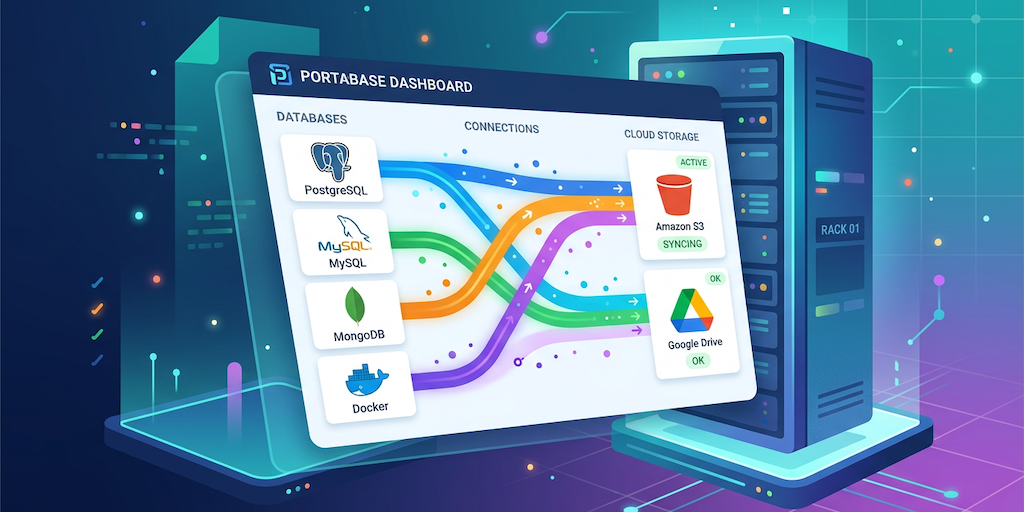
Lors de mes pérégrinations webesques pour vous trouver des nouveautés et assurer mon flux hebdomadaire de Pépites du Lundi matin, je suis tombé sur un outil de sauvegarde compatible avec de nombreux environnements de bases de données ainsi que d’un truc que je trouve génial personnellement … mais je tease 😉 … laissez moi vous présenter Portabase !
La pépite du Lundi matin : Plausible

Mal dormi cette nuit :(… La température n’est pas descendue en dessous de 27 °C… Bref, un peu dans le brouillard ce matin, mais cela ne m’empêche pas (pas encore, en tout cas…) de vous trouver une nouvelle pépite pour ce lundi difficile. Aujourd’hui, c’est Plausible, que j’ai découvert dimanche ! Plausible se veut tout simplement […]
Entretien avec Loïc Fontaine et Maxime de Tourtier, associés fondateurs de Ascenzia

Encore en entretien ! Cette fois-ci, ce n’est pas un, mais deux associés que j’ai eu la chance de rencontrer il y a quelque temps. Maxime, Loïc et leur collègue Laurent forment un trio à la tête d’une nouvelle startup française spécialisée en IA, Ascenzia. « Une de plus ! », me direz-vous. Sauf que leur stratégie est différente de ce qu’on peut lire régulièrement : elle répond à un besoin qui se fait de plus en plus nécessaire aujourd’hui : la gestion et le filtrage du shadow AI en entreprise.
Entretien avec Gaël Simonneaux, dirigeant de NaoShift

Coucou les gens ! Aujourd’hui, après la présentation de la solution de Naoshift, nous allons parler de l’homme qui se cache derrière ce projet, de son parcours ainsi que de la genèse de sa nouvelle startup, à travers un entretien que nous avons réalisé ensemble il y a environ une semaine. Si vous avez l’âme d’un entrepreneur, cela pourrait vous intéresser !