

Lors de la préparation initiale de ScaleIO (voir ce premier billet), on a installé l’ensemble des packages, dont le SDS évidemment, mais aussi la partie cliente, SDC. A l’issue, tous nos noeuds sont hybrides SDS/SDC. Afin de commencer à se familiariser avec l’administration de ScaleIO (qui se passe, pour l’essentiel via ligne de commande), je vous propose d’y aller pas à pas et d’expliquer chacune des commandes. Rassurez-vous, dans ce billet, vous aurez l’impression que je maîtrise déjà la bête, ce qui est faux évidemment, mais rappelez-vous que j’ai passé quelques heures à découvrir le produit, lire la doc et faire plusieurs essais et bidouilles avant de vous proposer ce scénario « lissé » 🙂
On se lance ?
Par défaut, comme vous pouvez le voir ci-dessous, nous partons d’un SDS de 3 noeuds où sont déjà définis un « protection domain » (je ne rentrerai pas dans le détail de ce concept dans ce billet, il nous en faut au moins un, c’est cas, pour l’instant ça nous suffit) et un storage pool (un groupe de serveurs SDS). Au total nous disposons de 200 Go utilisables (100 Go étant dé-facto réservé à la protection des données écrites) :
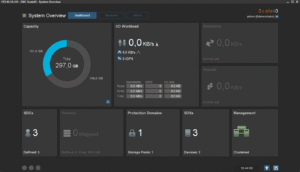
Pour la clarté de la présentation, j’ai renommé, via la GUI, le cluster en « scaleio », le protection domain en « poc » et le pool créé par défaut en « pool0 » :
Première chose à faire, découvrir un peu plus en détail notre « environnement » via des commandes sur le MDM.
D’abord, on se loggue sur le MDM :
|
1 2 3 |
[root@ionode1 ~]# scli --login --username admin Enter password: Logged in. User role is Administrator. System ID is 534a501d0eaa34a4 |
Ensuite quelques commandes de type « query », comme la liste des SDS :
|
1 2 3 4 5 6 7 |
[root@ionode1 ~]# scli --query_all_sds Query-all-SDS returned 3 SDS nodes. Protection Domain 5ecdf20100000000 Name: poc SDS ID: ad67947100000002 Name: SDS_[172.16.16.134] State: Connected, Joined IP: 172.16.16.134 Port: 7072 SDS ID: ad67947000000001 Name: SDS_[172.16.16.121] State: Connected, Joined IP: 172.16.16.121 Port: 7072 SDS ID: ad67946f00000000 Name: SDS_[172.16.16.119] State: Connected, Joined IP: 172.16.16.119 Port: 7072 |
… la liste des SDC (3 pour l’instant, comme indiqué précédemment) :
|
1 2 3 4 5 6 7 8 9 10 11 12 |
[root@ionode1 ~]# scli --query_all_sdc MDM restricted SDC mode: Disabled Query all SDC returned 3 SDC nodes. SDC ID: 933759a300000000 Name: N/A IP: 172.16.16.121 State: Connected GUID: EBE3CD67-EE13-4ECE-AB7C-66286A90058A Read bandwidth: 0 IOPS 0 Bytes per-second Write bandwidth: 0 IOPS 0 Bytes per-second SDC ID: 933759a400000001 Name: N/A IP: 172.16.16.119 State: Connected GUID: C6F25E05-01E2-4994-97B5-596013E8705F Read bandwidth: 0 IOPS 0 Bytes per-second Write bandwidth: 0 IOPS 0 Bytes per-second SDC ID: 933759a500000002 Name: N/A IP: 172.16.16.134 State: Connected GUID: 0296A03C-9DC4-4C48-894D-41C798F52F89 Read bandwidth: 0 IOPS 0 Bytes per-second Write bandwidth: 0 IOPS 0 Bytes per-second |
… Ok, donc tout cela parait cohérent. Histoire que les commandes suivantes soient plus claires, je vous propose de renommer nos SDS et SDC par leur nom de host :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
[root@ionode1 ~]# scli --rename_sds --sds_id ad67947000000001 --new_name ionode1 Successfully renamed SDS with ID ad67947000000001 [root@ionode1 ~]# scli --rename_sds --sds_id ad67947100000002 --new_name ionode2 Successfully renamed SDS with ID ad67947100000002 [root@ionode1 ~]# scli --rename_sds --sds_id ad67946f00000000 --new_name ionode3 Successfully renamed SDS with ID ad67946f00000000 [root@ionode1 ~]# scli --query_all_sds Query-all-SDS returned 3 SDS nodes. Protection Domain 5ecdf20100000000 Name: poc SDS ID: ad67947100000002 Name: ionode2 State: Connected, Joined IP: 172.16.16.134 Port: 7072 SDS ID: ad67947000000001 Name: ionode1 State: Connected, Joined IP: 172.16.16.121 Port: 7072 SDS ID: ad67946f00000000 Name: ionode3 State: Connected, Joined IP: 172.16.16.119 Port: 7072 |
… on fait de même pour les SDC :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
[root@ionode1 ~]# scli --rename_sdc --sdc_id 933759a300000000 --new_name ionode1 Successfully renamed sdc with ID 933759a300000000 to ionode1 [root@ionode1 ~]# scli --rename_sdc --sdc_id 933759a400000001 --new_name ionode3 Successfully renamed sdc with ID 933759a400000001 to ionode3 [root@ionode1 ~]# scli --rename_sdc --sdc_id 933759a500000002 --new_name ionode2 Successfully renamed sdc with ID 933759a500000002 to ionode2 [root@ionode1 ~]# scli --query_all_sdc MDM restricted SDC mode: Disabled Query all SDC returned 3 SDC nodes. SDC ID: 933759a300000000 Name: ionode1 IP: 172.16.16.121 State: Connected GUID: EBE3CD67-EE13-4ECE-AB7C-66286A90058A Read bandwidth: 0 IOPS 0 Bytes per-second Write bandwidth: 0 IOPS 0 Bytes per-second SDC ID: 933759a400000001 Name: ionode3 IP: 172.16.16.119 State: Connected GUID: C6F25E05-01E2-4994-97B5-596013E8705F Read bandwidth: 0 IOPS 0 Bytes per-second Write bandwidth: 0 IOPS 0 Bytes per-second SDC ID: 933759a500000002 Name: ionode2 IP: 172.16.16.134 State: Connected GUID: 0296A03C-9DC4-4C48-894D-41C798F52F89 Read bandwidth: 0 IOPS 0 Bytes per-second Write bandwidth: 0 IOPS 0 Bytes per-second |
Notre petit cluster est prêt pour commencer à bosser. Nous allons d’abord créer un nouveau volume de 30 Go :
|
1 2 3 4 5 6 7 8 |
[root@ionode1 ~]# scli --add_volume --protection_domain_name poc --thin_provisioned --storage_pool_name pool0 --volume_name vol0 --size_gb 30 Warning: Rounding up the volume size to 32 GB Successfully created volume of size 32 GB. Object ID 88d601a800000000 [root@ionode1 ~]# scli --query_all_volumes Query-all-volumes returned 1 volumes Protection Domain 5ecdf20100000000 Name: poc Storage Pool a9b17e7900000000 Name: pool0 Volume ID: 88d601a800000000 Name: vol0 Size: 32.0 GB (32768 MB) Unmapped Thin-provisioned |
>
Ensuite, on va l’affecter au client SDC ionode1 (la machine qui fait également office de MDM primaire) :
|
1 2 |
[root@ionode1 ~]# scli --map_volume_to_sdc --volume_name vol0 --sdc_name ionode1 Successfully mapped volume vol0 to SDC ionode1 |
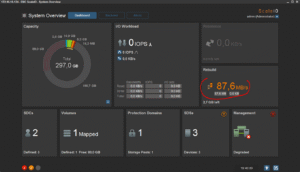
En retournant sur la GUI, on constate qu’effectivement, le nouveau volume est bien là et mappé sur un de nos clients :
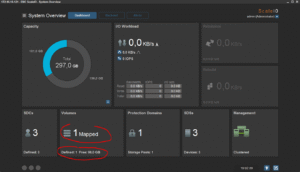
Il en nous reste plus qu’à préparer et utiliser notre volume. On passe donc du coté « client ». Première chose, faire un rescan sur le driver ScaleIO :
|
1 2 3 4 5 6 7 8 |
[root@ionode1 ~]# /opt/emc/scaleio/sdc/bin/drv_cfg --query_vols Retrieved 0 volume(s) [root@ionode1 ~]# /opt/emc/scaleio/sdc/bin/drv_cfg --rescan Calling kernel module to refresh MDM configuration information Successfully completed the rescan operation [root@ionode1 ~]# /opt/emc/scaleio/sdc/bin/drv_cfg --query_vols Retrieved 1 volume(s) VOL-ID 88d601a800000000 MDM-ID 534a501d0eaa34a4 |
Notre driver ScaleIO SDC a bien détecté le nouveau volume. Maintenant, c’est coté OS client que ça se passe. Sous Linux, les devices ScaleIO sont identifiés par des /dev/sciniX. On va donc tout simplement inspecter ça (là les linuxiens ne seront pas perdus), trouver le nouveau volume, le formatter et le monter !
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
[root@ionode1 ~]# ls /dev/scinia /dev/scinia [root@ionode1 ~]# fdisk -l /dev/scinia Disk /dev/scinia: 34.4 GB, 34359738368 bytes 64 heads, 32 sectors/track, 32768 cylinders Units = cylinders of 2048 * 512 = 1048576 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disk identifier: 0x00000000 [root@ionode1 ~]#mkfs -t ext4 Usage: mkfs [-V] [-t fstype] [fs-options] device [size] [root@ionode1 ~]# mkfs -t ext4 /dev/scinia mke2fs 1.41.12 (17-May-2010) Filesystem label= OS type: Linux Block size=4096 (log=2) Fragment size=4096 (log=2) Stride=0 blocks, Stripe width=0 blocks 2097152 inodes, 8388608 blocks 419430 blocks (5.00%) reserved for the super user First data block=0 Maximum filesystem blocks=4294967296 256 block groups 32768 blocks per group, 32768 fragments per group 8192 inodes per group Superblock backups stored on blocks: 32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632, 2654208, 4096000, 7962624 Writing inode tables: done Creating journal (32768 blocks): done Writing superblocks and filesystem accounting information: done This filesystem will be automatically checked every 25 mounts or 180 days, whichever comes first. Use tune2fs -c or -i to override. [root@ionode1 ~]# mount /dev/scinia /mnt [root@ionode1 ~]# df -h Filesystem Size Used Avail Use% Mounted on /dev/mapper/vg_ionode1-lv_root 50G 2.9G 44G 7% / tmpfs 939M 287M 653M 31% /dev/shm /dev/sda1 477M 80M 373M 18% /boot /dev/mapper/vg_ionode1-lv_home 45G 52M 43G 1% /home /dev/scinia 32G 48M 30G 1% /mnt |
C’est terminé, le filesystem est monté et opérationnel. Avant de publier ce billet, j’ai fait quelques petits tests rapides que je vous livre « brut de décoffrage » comme on dit :
|
1 2 3 4 5 6 7 8 |
[root@ionode1 ~]# dd if=/dev/zero of=/mnt/seq_4k bs=4K count=100000 100000+0 records in 100000+0 records out 409600000 bytes (410 MB) copied, 2.7716 s, 148 MB/s [root@ionode1 ~]# dd if=/dev/zero of=/mnt/seq_1M bs=4M count=1000 1000+0 records in 1000+0 records out 4194304000 bytes (4.2 GB) copied, 69.0931 s, 60.7 MB/s |
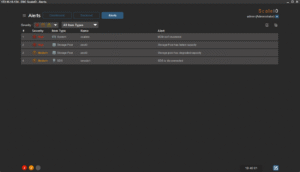
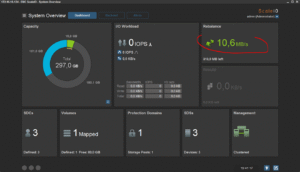
J’ai également réalisé des copies de petits de fichiers divers (copy de toute la hiérarchie « /usr » d’un de mes Linux vers le volume ScaleIO). Tout cela se comporte très bien. En supplément, voici une petite série de copies d’écran de la GUI pendant les copies et tests divers zé variés :
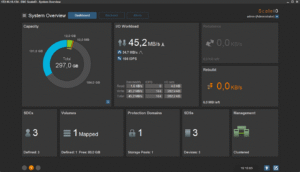

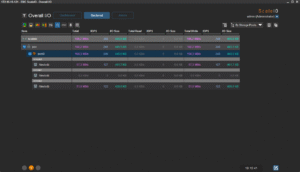
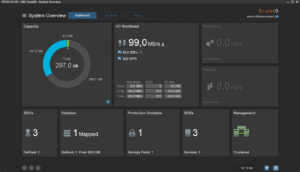
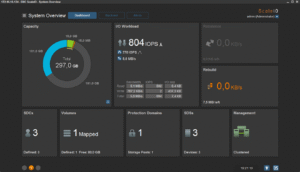
Enfin, histoire de tester un peu la robustesse du système, j’ai tout simplement rebooté un des noeuds. Le cluster s’est un peu « affolé » pendant quelques temps, mais j’ai pu constater une certaine forme d’admiration toute « geek » que celui-ci a tout de suite commencé à reconstruire les données manquante pour retrouver au plus vite la « double-copie » de chaque bloc de donnée. Ensuite, dès que le noeud en question est revenu online (au bout d’une trentaine de secondes), la reconstruction s’est transformée en « rebalance ». En effet, certains des blocs qui étaient déjà recopiés se son retrouvé « en triple » et le cluster a donc logiquement ré-équilibré (et supprimer du même coup) les copies inutiles.
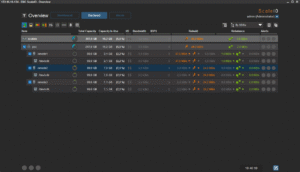
Bref… sans aller encore trop loin dans le fonctionnement (je testerai aussi l’ajout d’un nouveau noeud dans un prochain billet) ScaleIO semble assez « magique » dans son approche de la répartition de charge et sa gestion des pannes.
A suivre !