
Il y a quelques jours, un projet compliqué nous a contraint à utiliser NSX d’une façon qui n’est pas celle qu’on utilise habituellement au quotidien. Pour des problématiques de debugging, nous avons utilisé les fonctions de micro-segmentation sur des segments de type « vlan » (transportZone VLAN). Il a fallu donc expliquer en détail, sans rendre cela trop indigeste, ni – a fortiori – illisible, le fonctionnement de NSX dans ce cas précis aux personnes impliquées…
Ce n’était pas une mince affaire … voyez le tableau ou pas? Et bien, justement, parlons du tableau. En général, quand je suis confronté à ce genre de chose, la meilleure solution que j’ai trouvé et qui marche bien si on la travaille comme il faut en amont, c’est LE BON VIEUX SCHEMA. Cependant, ce schéma devait, pour l’occasion, concentrer des concepts difficiles si on ne les exploite pas au quotidien, ainsi qu’un empilement de couches logicielles qui n’arrangeait rien. Bref.
Gros challenge pour moi, donc : comment expliquer « la micro-segmentation » utilisée via une transportZone « VLAN », en opposition au mode overlay GENEVE classique de NSX-T. C’est alors qu’après environ 2h de travail initial, j’ai eu une idée de génie, vous allez voir, c’est incroyable, inédit tout en étant totalement révolutionnaire : demander à mes potes de Twitter de me filer un coup de main. Inutile de dire que mon sang n’a même pas fait un tour et que je me suis précipité sur mon client Twitter illico. Il faut dire que depuis plus de 8 ans de blogging maintenant, j’ai désormais à mes cotés des pointures, que-dis-je, des GROSSES MARMULES sur tous les sujets, y compris sur NSX et le réseau en général, forcément.
Ni une, ni deux, j’ai posté ma première version « draft » du fameux schéma que je destinais à mes collègues pour essayer d’expliquer au mieux le sujet et voir ce qu’ils en pensaient. Alors, je ne vais pas prendre quatre chemins, j’ai reçu beaucoup de retours (grand merci : mail, Slack, réponse à mes tweets et même un coup de fil ^^). Du coup, comme souvent ça a discuté pas mal (big up à Alexis et Timo, en particulier). C’était tellement intéressant que je nous pouvais pas passer sous silence ces échanges si constructifs.
Vous savez tout sur ce billet. Maintenant, après cette énorme introduction, voici donc le fameux schéma et les remarques/explications qui sont derrières :
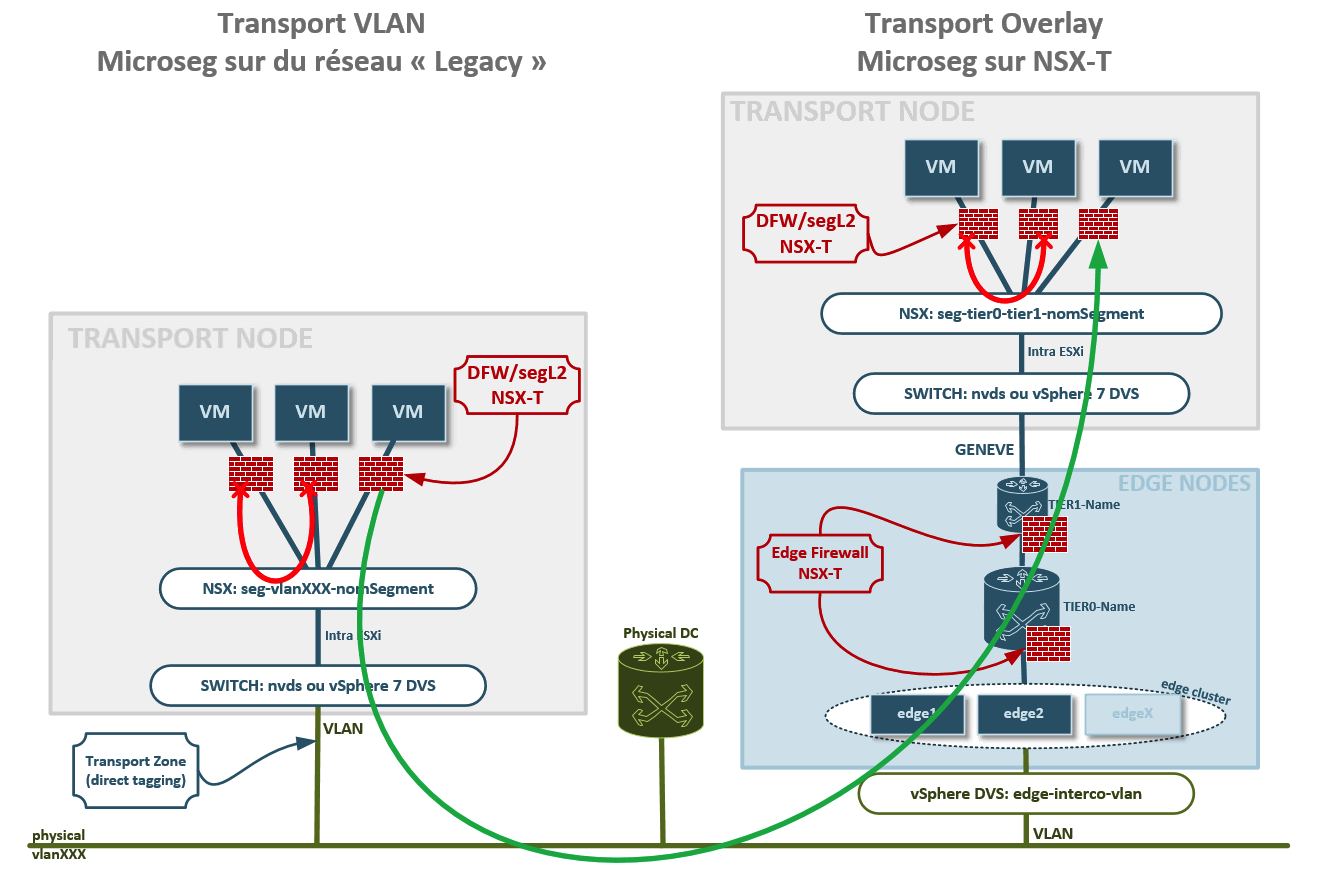
D’abord, rappelez-vous l’objectif initial : résumer, sans les rendre illisible ni incorrect, les deux méthodes que propose NSX-T pour gérer des flux entre VM/container et « le reste du monde ». C’est important d’avoir cela en tête car, pour les plus acérés d’entre-vous, il manquera sans doute des choses, certaines parties seront simplifiées etc. Pour autant, voilà les points importants qui doivent accompagner ce schéma.
Le concept de micro-segmentation : ça va mieux en le disant et finalement, sans avoir « appris quoi que ce soit » quand Timo m’en a parlé, cela donne de la profondeur au concept. La micro-segmentation est un « raccourci » pour parler, en fait, de segmentation L2. L’objectif est précis : pouvoir isoler des flux typiquement Est-Ouest au sein d’un même VLAN logique (un segment nsx étant, fondamentalement l’équivalent d’un vlan). C’est pour cela que quand on parle de micro-segmentation il ne faut pas galvauder les choses et n’afficher qu’une seule VM, par exemple, mais absolument en présenter au moins deux sur un même segment. Pour tout vous dire ma première version ne comportait qu’une VM et autant Timo que Alexis m’on fait remarquer qu’il faudrait en mettre plusieurs. Certes. Certains diront qu’on joue un peu sur les mots, une policy NSX s’appliquant à des flux autant Est-Ouest que Nord-Sud, maiiiiiis, il faut savoir appeler un chat, un CHAT et surtout le matérialiser correctement (le concept, pas le chat, je suis clair ou bien ?).
Le flou autour du cluster edge : Là, il s’agit plus de la difficulté de toute représenter. Vous le voyez, j’ai représenté un regroupement « cluster edge » constitué de plusieurs VM qui semblent autonomes et sans hiérarchie ni intrication. En fait, c’est beaucoup plus complexe que cela et ça dépend en plus des paramètres que vous donnez à vos routeurs T0 ou T1. Vous pouvez faire de l’actif-actif, de l’actif-passif, avec un cluster de plusieurs VMs (2 ou plus) etc. Ce cluster edge mérite donc d’y passer 5 minutes à l’oral pendant l’explication ou avec une petite phrase spécifique dans votre légende.
Les flux (flèches rouge et flèche verte) : : là, j’ai longuement hésité entre « présenter les flux réseau » ou « ne pas les représenter », telle était la question. C’est toujours la limite d’un exercice contraint comme celui-ci, à savoir UN SEUL schéma. Il faut attention à ne pas le surcharger. Ces flux, vous l’avez sans doute compris, permettent de matérialiser la granularité de la micro-segmentation (à l’objet NSX). Au passage, sachez, si vous ne le saviez pas, qu’on peut décrir des objets aussi précis qu’une carte réseau au sein d’une machine virtuelle.
nvds ou dvSwitch v7 : effectivement, depuis vSphere 7, les transport nodes sont capable de s’appuyer directement sur les distributed vSwitchs plutôt que les nvds, connus depuis longtemps sur NSX-T. C’est une précision importante, mais qui a un coût en terme de lisibilité, brouiller un peu les pistes des équipements logiques traversés, en fonction de la version de vos environnements.
On le voit, un schéma simple, ça prend du temps malgré les apparences, ça nécessite des explications complémentaires (souvent) et surtout, ça se partage avant d’arriver à quelque chose de satisfaisant. La deuxième morale est plutôt évidente : discutez avec des gens, échangez vos points de vue, confrontez votre prose ou vos schémas techniques au « public visé » mais pas seulement. Tout ça reste fondamental pour une documentation et une information de qualité !
Si vous avez d’autres remarques, précisions, n’hésitez pas, ce billet est précisément là pour échanger, je pense que vous avez compris 🙂
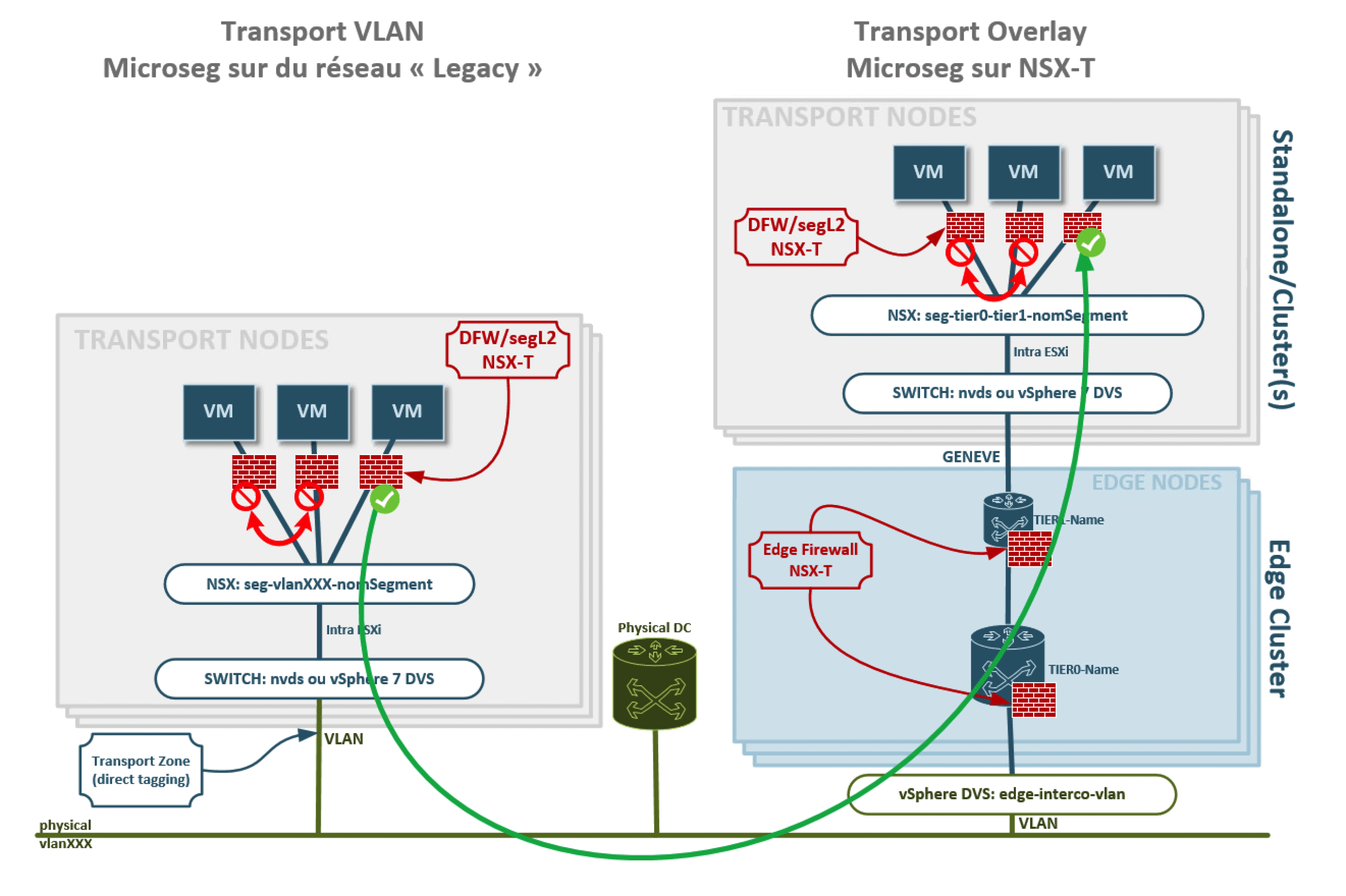
EDIT du 27 Janvier : Changements dans le schéma au niveau du Edge Cluster (merci à Fabien pour la remarque, @FabienKoessler). Voici la nouvelle version, qui simplifie, tout en étant plus correct, la partie « edge cluster ». Le paragraphe à ce sujet sur le billet reste pour autant valable ^^ :
0 réponse
5
4