

Nous exploitons déjà depuis plus de deux ans un cluster Kubernetes basé sur un empilement très complexe de couches OpenShift, mais aussi vSphere/VSAN/NSX-T, qui apporte un niveau de sécurité élevé avec le CNI Antrea (qui s’occupe du réseau du cluster Kube). Cela nécessite aussi un niveau d’expertise globalement très élevé, sans même parler du prix de ces couches…
Quand cette architecture a été validée il y a trois ans, cela avait du sens pour nous, mais nous ne connaissions pas alors l’environnement Kubernetes et cela nous semblait la solution la plus simple à l’époque : faire reposer la majorité des briques d’infrastructure sur des technologies que, par ailleurs, nous maîtrisions, à savoir NSX, vSphere et VSAN/VxRail.
Aujourd’hui, avec le recul et l’expérience, nous le disons tout net : ne faites pas ça ! Kubernetes est déjà assez compliqué en lui-même pour, au final, par souci de rapidité, vouloir s’appuyer sur un tel socle. Il vaut mieux partir directement sur un cluster bare metal, voire une solution full open source (par exemple Proxmox + Kubernetes ou du KubeVirt hybride VM et conteneurs).
Ceci étant, il faut bien entretenir ce cluster malgré tout, et c’est là que nous en arrivons au problème du jour (après cette longue introduction pour poser le contexte) : depuis quelques mois, avec l’aide de notre expert, qui nous aide depuis le début sur cette affaire, nous nous sommes rendu compte que le cluster OpenShift fonctionnait correctement, mais avait un souci pour communiquer avec notre instance NSX-T et faire vivre la topologie réseau via ce CNI, Antrea, chargé de gérer tout le réseau interne.
En creusant (je vous simplifie la chose, car l’investigation dure depuis plus de quatre mois désormais…), nous nous sommes aperçus que c’était la communication mTLS entre le CNI et le manager NSX-T qui ne se faisait plus : le certificat avait expiré et il était impossible de réintégrer en l’état l’autorité racine de certification qui avait servi à valider celui-ci… Nou’v’la bien, comme dit l’autre !
Au final, Alexis, après une investigation de plusieurs semaines et moi en jeune kube’padawan, a quelque peu détricoté le mécanisme de fonctionnement en faisant une sorte de reverse engineering de l’opérateur/cni pour comprendre comment remplacer ce certificat défaillant, en fournissant un certificat dont nous connaissions et maîtrisions totalement la chaîne d’autorités racine et intermédiaires…
La difficulté principale résidait dans l’établissement d’une connexion TLS entre un client doté d’un certificat émis par notre autorité (avec une nouvelle paire de clés) et le NSX Manager, configuré pour valider cette chaîne de confiance.
Comme le diable se cache dans les détails, la modification du certificat client attendu par NSX pour cette connexion ne peut se faire que grâce à un appel API. Du côté d’OpenShift, c’était « plus simple » dans le sens où il suffisait de modifier les secrets présents dans le CNI Antrea. L’erreur de départ se matérialisait par un message dans le conteneur tn-proxy : « tlsv1 alert unknown ca ».
Très exactement, voici l’état des conteneurs d’Antrea :

… donc un petit coup de curl pour modifier tout cela :
|
1 2 3 4 5 6 7 |
curl -k -u admin:<password> \ -X POST "https://nsxmanager-prd/api/v1/trust-management/principal-identities?action=update_certificate" \ -H "Content-Type: application/json" \ -d '{ "principal_identity_id": "74aaf92d-xxxx-49xx-9c1b-xxxxxxxxxx", "certificate_id": "xxxxxxxxx-d410-41xx-9f10-xxxxxxxxx" }' |
L’ID de certificat se trouve directement dans l’interface, dans la partie de gestion des certificats de NSX-T :
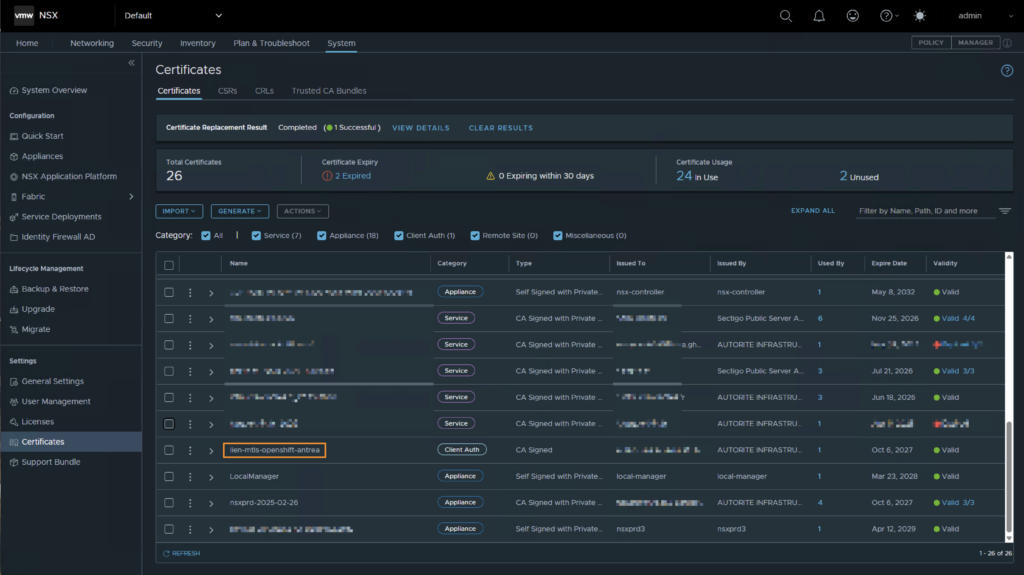
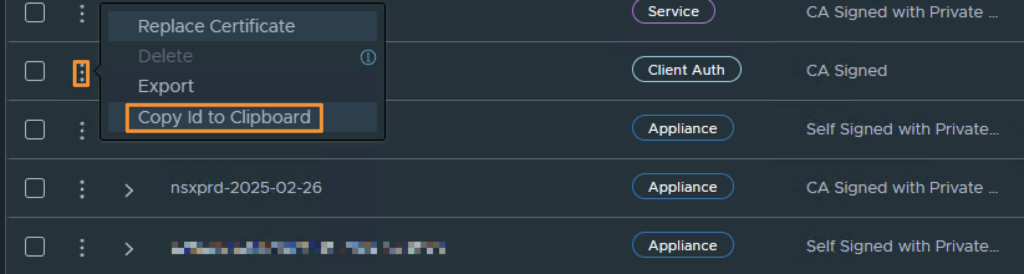
Le secret à remplacer du côté du CNI Antrea s’appelle nsx-cert, dans le namespace vmware-system-antrea.
Après ce changement, tout rentre dans l’ordre : le CNI se reconnecte au manager NSX et tout le monde est content… surtout les administrateurs !
Un grand merci à Alexis qui n’a rien lâché durant plusieurs mois pour trouver la solution. A noter qu’on a bien sûr appelé Broadcom/VMware … cela a pris 15 jours … sans aucune avancée notable. En désespoir de cause, nous avons préféré passer du temps et a vraiment progressé pour finalement arriver à la solution. Well done, camarade (au passage ce troubleshooting était passionnant et j’ai énormément appris à cette occasion, comme quoi, rien ne vaut la prod) !
Je disais il y a 1 an environ « Kubernetes, strange new world » … new, évidemment, strange sans doute, world je ne pouvais pas dire mieux je pense !
